


最近我在测试 Seedance 2.0 的时候,发现一个很关键的问题:
很多人用 AI 做视频,都是直接丢一张参考图,然后让模型“动起来”。
但实际生成出来以后,经常会出现这些问题:
人物一动就变脸;
镜头推进之后五官崩掉;
手部动作变形;
服装细节前后不一致;
视频看起来很惊艳,但角色完全不像原图了。
后来我发现,想让 Seedance 2.0 生成更稳定的视频,关键不是单纯把提示词写得更长,而是要先把工作流拆对。
我现在更推荐的流程是:
原始参考图 → 生成角色卡 → 编写专业分镜提示词 → 用 Seedance 2.0 生成视频。
这个流程比直接“图生视频”稳定很多,尤其适合做 AI 角色短片、虚拟 IP、AI 美女视频、产品广告和剧情分镜。
一、为什么不要直接用参考图生成视频?
很多人第一次玩 Seedance 2.0,都会这么操作:
上传一张人物图;
输入一句“让这个人物动起来”;
等待视频生成。
但这里有一个问题:
单张参考图提供的信息太少。
比如一张正面半身图,只能告诉模型:
这个人正面大概长什么样;
发型是什么样;
服装大概是什么风格;
画面整体是什么氛围。
但它不知道这个人物的侧面、背面、手部动作、表情变化、身体比例,以及不同角度下应该如何保持一致。
所以只要视频里出现转身、挥手、走动、比心、回头、表情变化这些动作,模型就很容易开始“自由发挥”。
结果就是:
第一帧像原图,后面越来越不像;
正脸还行,一转头就换人;
手一动就开始多手指;
服装细节在不同镜头里变来变去。
所以,直接用单张图生成视频,不是不行,而是不够稳定。
二、先做角色卡:让 AI 真正理解这个角色
我现在做 AI 视频,第一步不是直接生成视频,而是先做一张角色卡。
角色卡可以理解成:
给 AI 视频模型准备的一份人物视觉说明书。
它要把一个角色的关键信息尽量完整地展示出来,比如:
正面视图;
侧面视图;
背面视图;
多种表情特写;
手部不同动作;
发型、服装、身材比例、气质保持一致。
这样后面生成视频时,模型就不是只参考一张单薄的正脸图,而是有了更完整的人物信息。
你可以把原始参考图上传给 GPT Image 2,然后输入这个提示词:
把我生成这张照片女主角的角色卡片:包含正面侧面背面三视图,以及多表情面部特写,和手部不同动作的特写,保持女主角的外貌发型身材服饰气质完全不变。如果你要做男角色、产品角色、IP 形象,也可以把“女主角”替换掉。
比如:
把我上传的这个 IP 形象生成一张角色卡片:包含正面、侧面、背面三视图,以及多种表情面部特写和手部动作特写。要求保持角色的五官、发型、服装、身材比例、颜色风格和整体气质完全不变。
这一张图很关键,因为它会决定后面视频生成时角色能不能稳住。
三、为什么不是先做分镜图?
很多人会想:
既然我要做视频,那我是不是应该先生成几张分镜图,然后再把分镜图拿去做视频?
这个思路看起来很专业,但实际用 AI 做视频时,不一定是最优解。
原因很简单:
分镜图本身也是 AI 重新生成出来的,它可能已经改变了角色。
比如你先让 AI 生成 4 张分镜图:
第一张角色还像原图;
第二张脸型稍微变了一点;
第三张发型细节变了;
第四张衣服和眼神又变了。
然后你再把这些不完全一致的分镜图拿去生成视频,Seedance 2.0 看到的就不是一个稳定角色,而是一组已经发生偏移的图。
它就会更难判断:
到底哪个才是主角?
五官应该参考哪一张?
衣服细节应该以哪张为准?
镜头切换时人物要不要变化?
所以我更推荐:
不要先把参考图变成分镜图,而是先把参考图扩展成角色卡,再用文字分镜去控制视频。
角色卡负责稳定人物。
分镜提示词负责控制镜头。
Seedance 2.0 负责生成最终视频。
这个逻辑会稳定很多。
四、第二步:让 Codex 帮你写专业分镜提示词
有了角色卡之后,下一步就是写分镜提示词。
这里不要只写一句:
让这个人物在世界杯现场挥手。这种提示词太粗糙了。
Seedance 2.0 不知道你要什么景别、什么动作、什么节奏、什么镜头运动,也不知道这个视频应该像直播画面、电影镜头,还是短视频广告。
更好的方式是,让 Codex 帮你生成一个专业的 10 秒分镜提示词。
比如我想做一个世界杯女球迷的视频,就可以这样写:
给我一个专业的10秒分镜提示词,要求:真实的2030年世界杯直播,第60分钟,中国和巴西一比一战平,镜头转到一名美丽的中国队女球迷,她自然地露出微笑,挥手并送出飞吻,并对着镜头比出爱心手势。这句话的核心是告诉 Codex:
场景是什么;
时间点是什么;
人物是谁;
她要做什么动作;
视频大概多长;
画面风格是什么。
然后让 Codex 帮你扩写成真正适合视频模型理解的分镜提示词。
你也可以用下面这个通用模板:
请帮我写一个专业的 10 秒 AI 视频分镜提示词。
视频场景:
【填写你的场景】
主角:
参考图中的角色,必须保持外貌、发型、服装、身材比例和气质一致。
动作设计:
【填写你希望角色做什么】
镜头要求:
请拆成 3 到 4 个镜头,每个镜头包含:
景别、人物动作、镜头运动、画面氛围、环境声音。
文字要求:
如果画面中出现文字,必须全部使用中文,不要出现英文、拼音、乱码或无意义文字。
输出要求:
请直接输出可以用于 Seedance 2.0 的完整视频生成提示词。
五、一个完整的 10 秒分镜提示词示例
比如世界杯女球迷这个案例,可以扩展成这样:
请根据参考角色卡生成一段真实世界杯直播风格的 10 秒 AI 视频。
整体要求:
保持角色卡中女球迷的五官、发型、服装、身材比例和气质完全一致。画面为真实体育赛事直播质感,现场灯光明亮,背景有球迷、看台、国旗和大屏幕氛围,但不要喧宾夺主。人物动作自然,镜头运动平滑,不要变脸,不要换人,不要服装变化,不要肢体扭曲,不要多手指。
分镜设计:
0-2秒:
中景镜头,画面展示 2030 年世界杯比赛现场。中国队和巴西队 1:1 战平,现场气氛热烈。镜头从看台人群中缓慢推近,找到一名中国队女球迷。她穿着中国队元素的服装,表情自然,眼神看向球场方向。
2-5秒:
镜头切换到近景。女球迷注意到镜头正在拍她,转头看向镜头,露出自然微笑。她轻轻挥手,动作不要夸张,保持真实直播中的自然感。背景球迷继续欢呼,画面有轻微景深。
5-8秒:
镜头继续推近到胸像特写。女球迷对着镜头送出一个飞吻,表情开心但不过度夸张。动作流畅,手部自然,不要多手指,不要手部变形。
8-10秒:
镜头保持特写。女球迷对着镜头比出爱心手势,微笑停留一秒。画面有真实世界杯直播氛围,背景灯光和观众虚化,整体情绪热烈、积极、真实。
负面要求:
不要改变人物五官,不要换脸,不要改变发型,不要改变服装,不要变成其他人,不要出现乱码文字,不要出现错误中文,不要多手指,不要手部畸形,不要画面闪烁,不要风格突变。你会发现,这种提示词比一句“让她动起来”清楚很多。
它把视频拆成了:
开场镜头;
人物被镜头捕捉;
挥手;
飞吻;
比心;
结束定格。
这样 Seedance 2.0 更容易理解你到底想要什么。
六、第三步:角色卡 + 分镜提示词一起使用
真正生成视频的时候,不要只丢分镜提示词,也不要只丢参考图。
正确方式是:
上传角色卡,再粘贴完整分镜提示词。
如果你是通过 Codex 调用小云雀 Skill 或即梦 Skill,可以这样写:
请使用我上传的角色卡作为人物参考,并使用小云雀 Skill 调用 Seedance 2.0 生成一段 10 秒 AI 视频。
要求:
1. 严格保持角色卡中的人物外貌、发型、服装、身材比例和气质一致。
2. 按照下面的分镜提示词生成完整视频。
3. 镜头自然,动作流畅,画面稳定。
4. 不要换脸,不要变成其他人,不要多手指,不要肢体扭曲,不要乱码文字。
5. 如果生成过程中需要理解人物,请优先参考角色卡,而不是自行重新设计角色。
分镜提示词如下:
【粘贴你的完整分镜提示词】如果你用的是即梦 Skill,也可以把“小云雀 Skill”替换成“即梦 Skill”。
七、如何让 Codex 调用小云雀生成视频?
如果你想让 Codex 直接帮你调用视频生成工具,可以提前把小云雀接入 Codex。
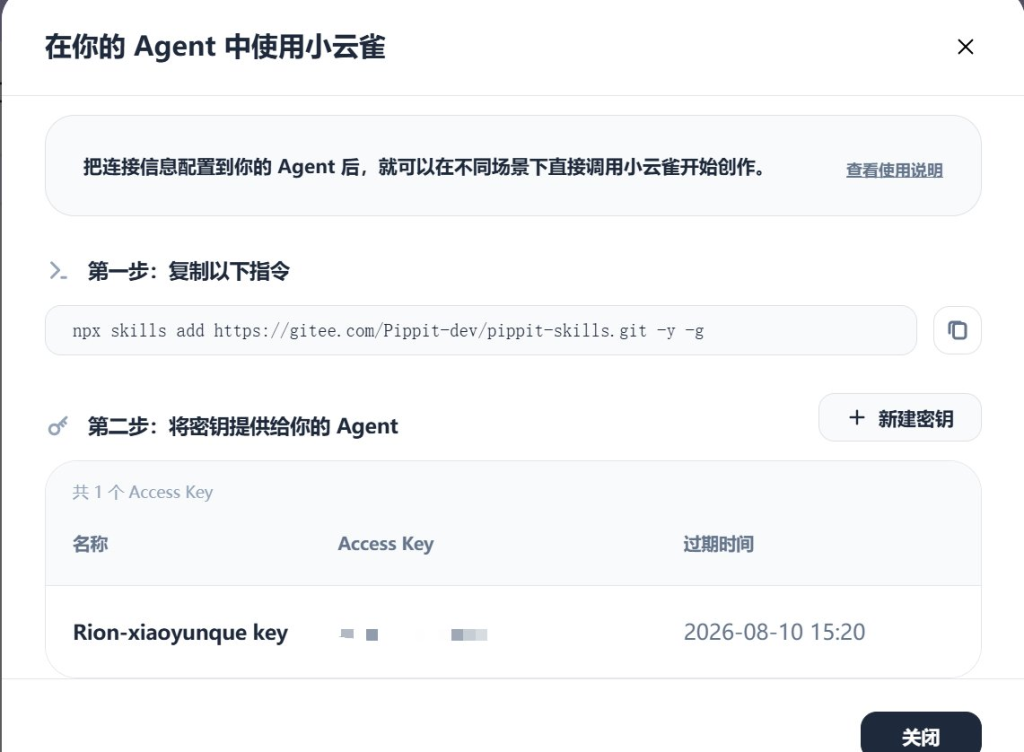
大概流程是:
第一步,登录小云雀网页版。
第二步,找到「链接 Agent」或者类似入口。
第三步,根据页面提示生成 API Key。
第四步,把 API Key 配置到 Codex 或对应的 Skill 里。
第五步,之后就可以直接让 Codex 调用小云雀生成视频。
配置完成后,你可以直接对 Codex 说:
用小云雀 Skill 调用 Seedance 2.0 生成一个 10 秒视频。
参考图:
【上传角色卡】
视频提示词:
【粘贴完整分镜提示词】这一步的价值在于:
你不用来回切工具;
不用手动复制很多参数;
可以把“写提示词 + 调用生成 + 迭代修改”都放到一个 Agent 流程里。
对我这种经常要做 AI 视频、教程演示、短视频素材的人来说,这种流程会更顺手。
八、完整工作流总结
整个流程可以总结成 4 步。
Step 1:准备一张清晰参考图
参考图最好满足几个条件:
人物主体清楚;
脸部细节清晰;
发型和服装完整;
背景不要太复杂;
最好是原创角色或你有授权的素材。
不要一开始就用特别复杂的多人图、遮挡图、背光图,不然后面角色卡也容易生成不稳定。
Step 2:用 GPT Image 2 生成角色卡
把参考图上传给 GPT Image 2,输入:
请根据我上传的参考图,生成一张角色卡。
角色卡内容包括:
1. 正面视图
2. 侧面视图
3. 背面视图
4. 多表情面部特写
5. 手部不同动作特写
要求:
保持角色的外貌、发型、身材比例、服装、气质完全不变。
不要改变角色身份,不要换脸,不要改变服装风格。
整体排版清晰,适合作为后续 AI 视频生成的角色参考图。生成后,检查角色卡是否稳定。
重点看:
脸有没有变;
发型有没有变;
服装有没有变;
侧面和背面是否合理;
手部动作是否可用。
如果角色卡本身已经崩了,就不要继续往下做,先重新生成角色卡。
Step 3:让 Codex 生成专业分镜提示词
然后让 Codex 根据你的创意写分镜。
模板如下:
请帮我写一个专业的 10 秒 AI 视频分镜提示词。
视频主题:
【填写主题】
场景设定:
【填写场景】
主角设定:
参考角色卡中的人物,保持外貌、发型、服装、身材比例和气质完全一致。
动作设计:
【填写动作】
镜头语言:
请拆成 3 到 4 个镜头,每个镜头写清楚景别、动作、镜头运动和画面氛围。
风格要求:
【例如:真实直播风格 / 电影感 / 广告片质感 / 赛博朋克 / 纪录片风格】
负面要求:
不要换脸,不要变成其他人,不要多手指,不要肢体扭曲,不要服装变化,不要画面闪烁,不要乱码文字。
输出要求:
请直接输出可以用于 Seedance 2.0 的完整视频提示词。Step 4:角色卡 + 分镜提示词一起生成视频
最后,把角色卡和分镜提示词一起交给 Seedance 2.0。
如果你通过 Codex 调用,就用这个模板:
请使用我上传的角色卡作为人物参考,用小云雀 Skill 调用 Seedance 2.0 生成视频。
核心要求:
1. 严格保持角色外貌、发型、服装、身材比例和气质一致。
2. 按照下面的分镜提示词生成完整视频。
3. 镜头自然,动作流畅,画面稳定。
4. 不要换脸,不要变成其他人,不要多手指,不要肢体扭曲,不要乱码文字。
分镜提示词如下:
【粘贴完整分镜提示词】九、新手最容易踩的几个坑
1. 角色卡太花哨
角色卡不是海报,不要追求过度设计。
它的核心作用是让模型看懂角色,所以排版越清晰越好。
2. 分镜写得太满
10 秒视频不要写太多动作。
挥手、转头、走近、微笑、比心,这些动作比较稳。
快速跑动、复杂舞蹈、多人互动、打斗动作,容易崩。
3. 不写“不变项”
AI 视频最怕的就是默认自由发挥。
你一定要明确告诉它:
五官不变;
发型不变;
服装不变;
身材比例不变;
气质不变;
不要换脸;
不要多手指。
这些话看起来啰嗦,但非常有用。
4. 一开始就做长视频
建议先从 5 秒或 10 秒开始测试。
短视频跑稳定了,再去扩展更长的剧情镜头。
5. 用了不适合的参考图
如果参考图本身就模糊、脸小、遮挡严重、背景复杂,后面再怎么写提示词也很难稳定。
AI 视频生成的上限,很大程度上取决于你的参考素材质量。
十、这个工作流适合做什么?
这个方法我觉得特别适合几类内容。
第一类,AI 角色短片。
比如固定一个虚拟人物,让她在不同场景里完成动作和剧情。
第二类,AI 美女 / AI 模特视频。
角色一致性非常重要,不然每个镜头都像换人。
第三类,虚拟 IP 内容。
比如你有自己的 IP 形象,可以先做角色卡,再批量生成短视频素材。
第四类,产品广告视频。
产品也可以做“产品角色卡”,把正面、侧面、细节、使用场景整理出来,再用分镜提示词控制广告镜头。
第五类,剧情分镜测试。
先用 AI 快速生成 5 到 10 秒镜头,看这个创意是否成立,再决定是否继续扩展。
十一、总结
我现在做 Seedance 2.0 视频,更推荐这个流程:
不要只给一张图,也不要只写一句提示词。
更稳定的方式是:
先用参考图生成角色卡;
再用 Codex 写专业分镜提示词;
最后把角色卡和分镜提示词一起交给 Seedance 2.0。
角色卡解决的是“像不像同一个人”。
分镜提示词解决的是“镜头怎么拍”。
Seedance 2.0 负责把这两个信息整合成视频。
一句话总结:
AI 视频想要稳定,不是靠玄学抽卡,而是靠更清晰的前期设计。
你给模型的信息越完整,它自由发挥的空间就越小;
你把角色、动作、镜头、负面要求写得越清楚,最终视频就越接近你想要的效果。
这就是我目前测试下来,Seedance 2.0 比较实用的一套高阶工作流。
本文分享 Redman 实测整理的 Seedance 2.0 高阶视频生成流程:先用 GPT Image 2 根据参考图生成角色卡,再让 Codex 编写专业分镜提示词,最后通过小云雀或即梦 Skill 调用 Seedance 2.0 生成视频。这个方法可以提升 AI 视频中的角色一致性、镜头可控性和成片稳定性。
标签
#Seedance2 #AI视频 #小云雀 #即梦AI #Codex #GPTImage2 #AI分镜 #角色一致性 #图生视频 #AIGC教程